| 动态开辟内存 | 您所在的位置:网站首页 › ios cpu占用太高 › 动态开辟内存 |
动态开辟内存
|
编者按 性能优化,对游戏开发来说是一个需要不断钻研的课题,性能越好,游戏才会运行的更加顺畅,玩家的体验感才会更好。腾讯游戏学院专家、游戏客户端开发Leonn,将和大家分享UE手游在iOS平台上的内存分布和优化。(本文首发于腾讯游戏学院专家团月刊《EXP手册》) 文 | Leonn 腾讯游戏学院专家 游戏客户端开发 对于在iOS平台上运行的UE程序,经常会出现内存占用较高,xcode的内存统计和UE的统计有偏差的问题。本文将讨论下iOS上内存的管理机制,内存的组成,iOS特有的一些资源管理特性,以及UE程序针对iOS常见的内存瓶颈和优化。 
 iOS程序内存分配原理
iOS程序内存分配原理
1.1 iOS系统内存分配原理 iOS也是一个类linux的系统,所以基本的内存分配还是走的虚拟内存系统中page mapping和swap out那套,即虚拟内存访问缺页产生对物理内存的实际占用,以及对物理内存的唤入唤出(详细可以看前面的《Android内存分布和优化》的文章)。iOS上的page size 为16k, Swap out和compressed memory 关于swap out机制,由于移动端内存的寿命问题,没有实现传统虚拟内存那样的swap in/out机制,只有一些read-only的数据(例如代码)在被swap out的时候,会被直接从物理内存移除,而不会back up到磁盘文件上,下次swap in就直接重新加载,也就是非read only的page只要被访问就永远不可能唤出物理内存。 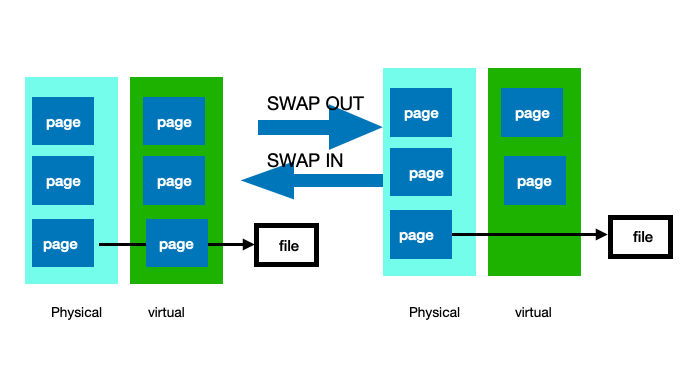
此外iOS还有额外的memory compress机制,即将一些不常用的内存压缩存储在内存中。 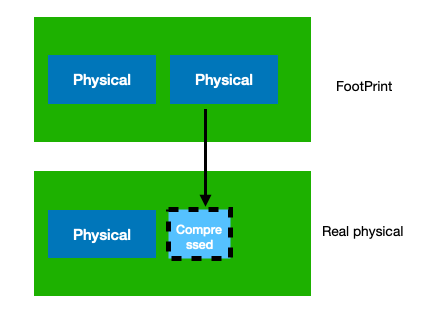
所以iOS中有个特有的表示内存占用的说法memory footprint就是值得压缩前的总大小,而不是当前的实际物理内存大小。 当系统内存吃紧的时候,系统会通过didrecievememorywarning通知程序,让程序自愿的释放一些内存,这时候如果程序仍然不能有效降低内存,进程就会被杀掉。 VM Object 在iOS内核中,使用一个叫做VM Object的对象表示在虚拟内存空间的一块被映射的内存区域(region),一个region是由几个连续的page组成,所以一个vm object region的起始地址必定是某个虚拟空间上page的起始地址。VM Object还记录了其他的一些信息,包括继承关系,读写权限,是否是wired(能不能被swap-out)。此外它还关联了一个pager,用来做内存映射,这个pager是default pager或者vnode pager的一种, default pager负责将虚地址VA跟物理地址PA做映射(即访问va缺页后将开辟物理内存),vnode pager直接将文件映射到虚地址空间(这样不经过内存直接读写文件)。 VM_Copy Vm object的pager除了可以是default pager或者vnode pager之外,还可以直接映射另外一个vm object,这时是为了做copy-on-write优化。这允许不同的vm object映射同一段page区域,直到其中一个vm object需要发生写入它才会copy出一个新的。在iOS系统下我们可以直接调用vm_copy代替memcpy来执行这种copy-on-write的copy,只要你copy后面不写入,就一直没有实际的copy开销。Vm_copy的唯一缺点是如果发生写入那么copy会存在延时,所以对于频繁的小内存的copy还是推荐直接memcpy。 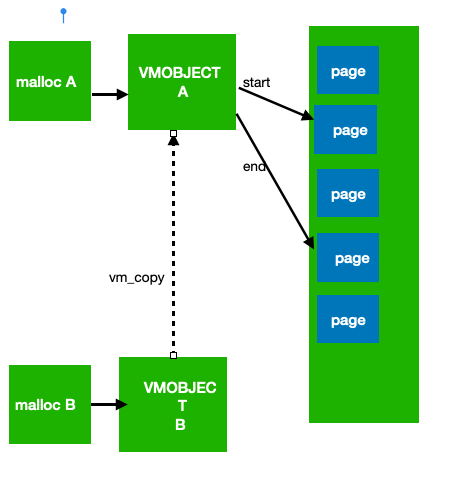
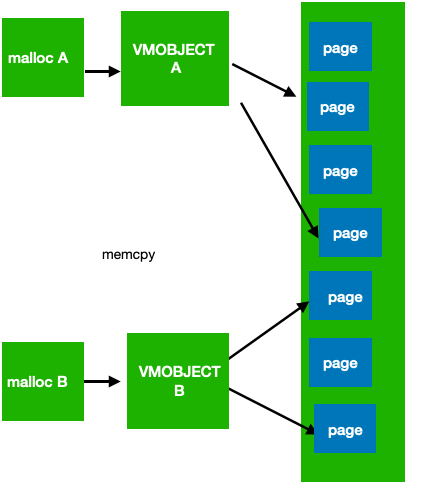
Vm_copy和memcpy 1.2 iOS系统内存的分配方式 在《Android内存分布和优化》中我们讲了使用malloc和mmap分配系统内存的原理和区别。这里我们详细讨论下他们在iOS上的特点。 vm_allocate 首先iOS上做mmap的函数是vm_allocate,它同Android上的mmap用法相当,即分配一个虚存,做物理内存或者文件映射。 Malloc 直接从堆上分配内存,并且这些内存会立即从虚拟内存映射物理内存,并且不会初始化内存内容。在iOS上malloc的底层实现细节如下: 小内存:小于几个pagesize的内存,malloc会从一个pool上分配,这个pool本身是由vm_allocate分配的虚存,这些虚存可能都是已经存在物理内存映射的了,这个池分配的粒度都是按照16字节对齐,所以我们用malloc也尽量16字节对齐,否则就存在了浪费。这个小内存池的预分配的大小有多大要取决于系统策略。 大内存:对于大于几个pagesize的内存,Malloc自动使用 vm_allocate,它只分配虚存,不立即映射物理内存,分配粒度为1个page大小(即16k),因为不同的vmobject是由不同的独立的page组成,这时如果malloc的大小没有16k对齐,也会产生较多的内存浪费。在这种情况,使用malloc和直接使用vm_allocate是相当的。 Calloc calloc同malloc不同的是,它在分配内存后,在使用前会保证将内存初始化为0。他比用malloc+memset要优化,因为memset发生时会立即产生缺页造成物理内存占用,然后初始化0,而calloc则是延迟的,它不会马上产生物理内存占用,而是要等得到真正这块内存被使用之前。我们应该完全使用calloc代替malloc+memset。 Malloc zone iOS上所有的内存分配都是来自于某个malloc zone的,每个zone有独立的内存池,默认的分配都是在default malloc zone上的。使用malloc zone有个好处是减少小内存池的浪费。我们知道内存池的浪费主要有两种来源,一种是对齐浪费,即为了匹配内存池的分配粒度,没有对齐的内存产生的浪费,如malloc一个17 byte的内存其实需要malloc 32byte,另一种则来源于对页的空白浪费,例如在频繁的分配内存后,会开辟大量的新page,这样在后面即使先后发生了一些释放,但是因为释放不集中在一个page上,也导致了很多page上只被少量的block占据,导致大量的空白部分的浪费。如果我们可以知道某些内存的生命周期是相同的,那么我们可以把它们在同样的一个zone上分配,这样我们在确定他们的生命周期全都到期后,可以对整个zone执行释放的操作,这样就杜绝了这两种浪费。在iOS下使用malloc zone 的相关接口是 malloc_create_zone 创建一个zone malloc_zone_malloc再某个zone上分配 malloc_destroy_zone 释放整个zone
 UE程序在iOS上的内存组成清单
UE程序在iOS上的内存组成清单
了解了iOS上的基本内存分配原理后,我们来统计我们iOS上的UE程序的内存组成。在对UE程序进行内存分析和优化过程中,我们要做的的第一件事就是获取一个完整的关于你程序的内存组成清单。UE的引擎内部提供了LLM,memreport等内存统计工具,但是这些只是UE能感知到的内存,我们需要能明确整个程序的内存被花到哪里了,以及为什么程序会因内存过高而产生问题。 2.1 iOS内存组成统计口径 Memory footprint Android上我们一般使用PSS,即程序(按分摊统计共享库)分配的实际物理内存大小来定义内存开销。iOS有所不同,iOS上通常使用memory footprint(下面简写为mem foot)这一个概念来定义内存开销,mem foot同实际占用的物理内存之间有一定差别。Mem foot在iOS上的定义是进程实际占用的物理内存+进程被压缩了的内存在压缩前的大小,即mem foot = resident + swapped (这里的swapped不是指swap out的意思,是前文说到的iOS的内存压缩机制)。所以从定义上看,所谓mem foot是指你的进程所可能触碰到的所有物理内存大小(尽管部分已经被压缩),这就是脚印的意思。 在xcode的allocater中,我们可以计算vm tracker中all中的resident+swapped的大小来得到mem foot值。如果是在代码中,则可以通过darwin内核的接口task_info获取TASK_VM_INFO来获取其中的phys_footprint来获得,darwin源码中关于phys_footprint的定义是 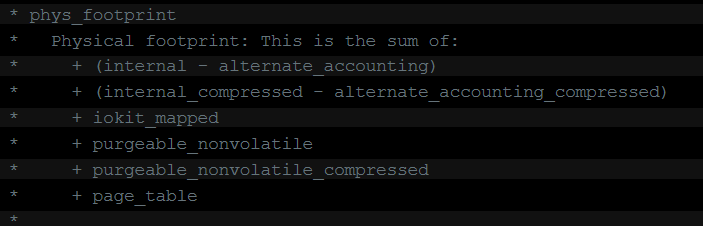 其中internal即除了显存外的resident内存,internal_compressed即指除了显存外的swapped部分,iokit_mapped一般就是(其实是不能使用purgeable memory的)显存,后面的purgeable是指使用purgeable memory中属性为nontvolatile的。关于purgeable memory后文再说。
可以说memery footprint 是iOS上统计内存占用的金标准。
XCode Gauge
当我们使用xcode运行游戏,会看到一个实时的显示内存的仪表盘,如下图
其中internal即除了显存外的resident内存,internal_compressed即指除了显存外的swapped部分,iokit_mapped一般就是(其实是不能使用purgeable memory的)显存,后面的purgeable是指使用purgeable memory中属性为nontvolatile的。关于purgeable memory后文再说。
可以说memery footprint 是iOS上统计内存占用的金标准。
XCode Gauge
当我们使用xcode运行游戏,会看到一个实时的显示内存的仪表盘,如下图
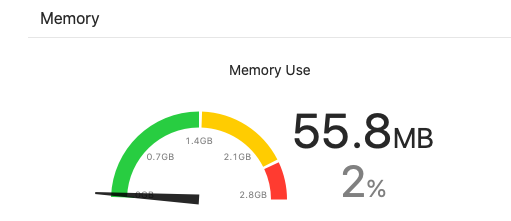 这个叫做xcode memory gauge,它统计的又是什么内存呢,其实它严格来说统计的不是memory footprint,它统计的是vmtracker里面dirty+swapped的值,那么什么是dirty内存呢,dirty是指实际占用的物理内存(resident)中那些一定不能被swap out出去的内存,前面提到iOS swap out机制时说,iOS上只有那些可读的文件等才能被swap out,这些能swap out的内存通常危害不大,在内存吃紧的时候可以部分被系统调度出物理内存,他们一般是各种文件映射,代码库,符号文件等,所以dirty才是程序动态分配的需要考虑的内存,xcode gause统计的是真正用户能够决定的内存脚印大小。他要比mem foot小一些,小了那些代码和文件的内存占用。
2.2 iOS程序主要内存构成
我们以memory footprint为统计标准来得到iOS的完整内存构成,最正确方便的方法是使用xcode的allocations工具,里面有个vm tracker,vm tracker就是用来跟踪程序的每个vmobject的,即每个虚拟内存区域的分配情况。在vm tracker里面做一个snapshots,就可以得到当前内存分配的一个快照。
这个叫做xcode memory gauge,它统计的又是什么内存呢,其实它严格来说统计的不是memory footprint,它统计的是vmtracker里面dirty+swapped的值,那么什么是dirty内存呢,dirty是指实际占用的物理内存(resident)中那些一定不能被swap out出去的内存,前面提到iOS swap out机制时说,iOS上只有那些可读的文件等才能被swap out,这些能swap out的内存通常危害不大,在内存吃紧的时候可以部分被系统调度出物理内存,他们一般是各种文件映射,代码库,符号文件等,所以dirty才是程序动态分配的需要考虑的内存,xcode gause统计的是真正用户能够决定的内存脚印大小。他要比mem foot小一些,小了那些代码和文件的内存占用。
2.2 iOS程序主要内存构成
我们以memory footprint为统计标准来得到iOS的完整内存构成,最正确方便的方法是使用xcode的allocations工具,里面有个vm tracker,vm tracker就是用来跟踪程序的每个vmobject的,即每个虚拟内存区域的分配情况。在vm tracker里面做一个snapshots,就可以得到当前内存分配的一个快照。
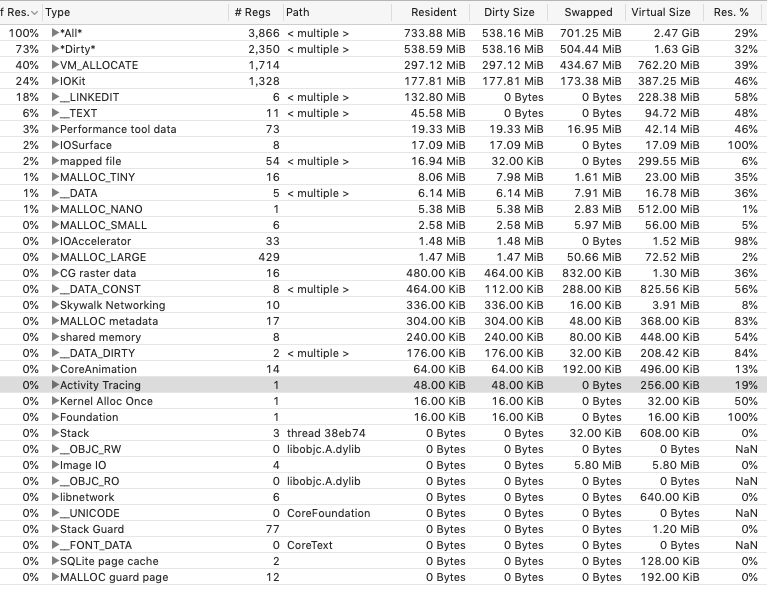 一个典型的vm tracker快照截图
其中All是指总的分类,all下面是各种细类,右面的resident dirty swapped分别指实际物理内存,不能被swap out出去的物理内存,以及被压缩的内存的压缩前大小,最后面的virtual size是虚存大小。我们把all中的resident+swapped就是总memory foot print。
下面是占据大头的几个细类:
IOKIt和IOSurface
:通常就是指我们GPU需要访问的内存,即显存
Performance tool data
:是实际运行没有的,Profile 工具本身内存。
Mappedfile
:文件映射,用于读写的文件,一般不占用很多dirty
__LINKEDIT和__TEXT
:代码段部分,即代码段内存,只读,他们一般不占dirty
__DATA
:代码的数据段,包括可读写的全局变量等。
Malloc_NANO/TINY/SMALL/LARGE
:这就是前面提到的iOS的malloc小内存池,nano/TINY指的就是文章最前提到的malloc zone。虽然默认的malloc是在default zone上分配的,但是系统还是会根据不同的大小再选择不同的zone。对于0-256B的malloc,系统会使用nano zone,nano zone比较特殊,它专门为小内存而优化,并且预先就vm_allocate了一块512M的虚拟内存空间做这个nano zone 的pool,这块空间处于堆底。对于更大一些的小内存分配,则会根据情况使用到tiny small large这三个zone 的pool。所以我们推荐大家在iOS上对于256b以内的内存分配直接走malloc,而不是UE的malloc,可能会得到更多的收益。
VM_ALLOCATE
:这个就是通过vm_allocate方法申请虚存后缺页触发的内存占用,在UE里面一定是大头,因为UE自己的Fmalloc在iOS上就是走的vm_allocate。又因为UE的fmalloc在做vm_allocate的时候传递的tag是255,所以在vmtracker中,所有体现为memory tag 255的vm就是UE的fmalloc。
2.3 UE程序内存组成清单
从vm tracker出发,在配合我们在《Android内存分布和优化》中提到的UE的自带的LLM机制,我们就可以构建UE程序在iOS平台上的内存完整清单了。它至少应该被分割成以下几个大部分:
一个典型的vm tracker快照截图
其中All是指总的分类,all下面是各种细类,右面的resident dirty swapped分别指实际物理内存,不能被swap out出去的物理内存,以及被压缩的内存的压缩前大小,最后面的virtual size是虚存大小。我们把all中的resident+swapped就是总memory foot print。
下面是占据大头的几个细类:
IOKIt和IOSurface
:通常就是指我们GPU需要访问的内存,即显存
Performance tool data
:是实际运行没有的,Profile 工具本身内存。
Mappedfile
:文件映射,用于读写的文件,一般不占用很多dirty
__LINKEDIT和__TEXT
:代码段部分,即代码段内存,只读,他们一般不占dirty
__DATA
:代码的数据段,包括可读写的全局变量等。
Malloc_NANO/TINY/SMALL/LARGE
:这就是前面提到的iOS的malloc小内存池,nano/TINY指的就是文章最前提到的malloc zone。虽然默认的malloc是在default zone上分配的,但是系统还是会根据不同的大小再选择不同的zone。对于0-256B的malloc,系统会使用nano zone,nano zone比较特殊,它专门为小内存而优化,并且预先就vm_allocate了一块512M的虚拟内存空间做这个nano zone 的pool,这块空间处于堆底。对于更大一些的小内存分配,则会根据情况使用到tiny small large这三个zone 的pool。所以我们推荐大家在iOS上对于256b以内的内存分配直接走malloc,而不是UE的malloc,可能会得到更多的收益。
VM_ALLOCATE
:这个就是通过vm_allocate方法申请虚存后缺页触发的内存占用,在UE里面一定是大头,因为UE自己的Fmalloc在iOS上就是走的vm_allocate。又因为UE的fmalloc在做vm_allocate的时候传递的tag是255,所以在vmtracker中,所有体现为memory tag 255的vm就是UE的fmalloc。
2.3 UE程序内存组成清单
从vm tracker出发,在配合我们在《Android内存分布和优化》中提到的UE的自带的LLM机制,我们就可以构建UE程序在iOS平台上的内存完整清单了。它至少应该被分割成以下几个大部分:
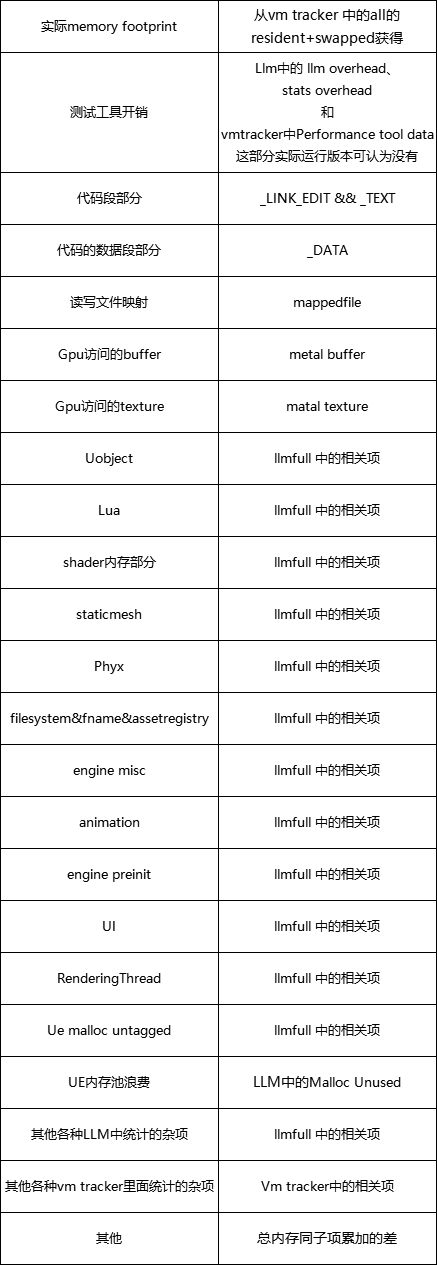 这是我们对于任何一个UE程序,可以得到的在iOS上的详细的内存分布情况,这里面有几个问题需要注意:
实际的总mem foot和下面各自项加起来可能是存在一定偏差的。
因为LLm中各个从UE Fmalloc出来的子项的总和其实也只是个vm_allocate的虚存大小,它实际上占用的物理内存脚印是要小一些的,另外LLM里面对metal texture和buffer的内存计算也是估计的,但是一般情况不会差别过大,我们只要了解这其中存在差值即可。
2.4 显存大小的统计
Llm统计的metal tex和metal buffer是UE统计的gpu访问的资源量,它同实际值是有偏差的,比如UE未考虑到使用purgeable memory,memryless等资源的内存减少,此外显存上还有除了tex和buffer之外的其他资源。所以如果想确定真实的gpu资源使用还是要看IOKIT的值,只是我们可以用metal tex 和buffer估计下大致的比例。另外在最新版本xcode的截帧工具中我们也可以看到一个细节的tex和buffer的显存,如下:
这是我们对于任何一个UE程序,可以得到的在iOS上的详细的内存分布情况,这里面有几个问题需要注意:
实际的总mem foot和下面各自项加起来可能是存在一定偏差的。
因为LLm中各个从UE Fmalloc出来的子项的总和其实也只是个vm_allocate的虚存大小,它实际上占用的物理内存脚印是要小一些的,另外LLM里面对metal texture和buffer的内存计算也是估计的,但是一般情况不会差别过大,我们只要了解这其中存在差值即可。
2.4 显存大小的统计
Llm统计的metal tex和metal buffer是UE统计的gpu访问的资源量,它同实际值是有偏差的,比如UE未考虑到使用purgeable memory,memryless等资源的内存减少,此外显存上还有除了tex和buffer之外的其他资源。所以如果想确定真实的gpu资源使用还是要看IOKIT的值,只是我们可以用metal tex 和buffer估计下大致的比例。另外在最新版本xcode的截帧工具中我们也可以看到一个细节的tex和buffer的显存,如下:
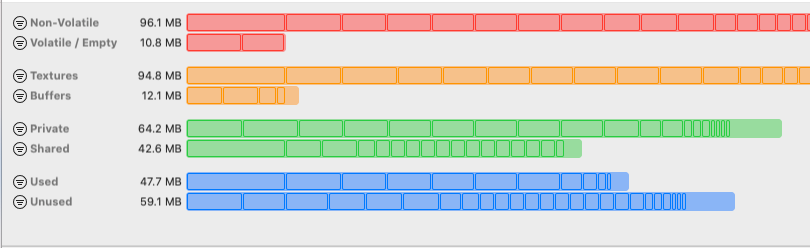 它可以显示详细的tex和buffer使用情况,但是内存值是明显偏大的,因为这里显示的是虚存值,不是物理内存,所以也只能参考。
它可以显示详细的tex和buffer使用情况,但是内存值是明显偏大的,因为这里显示的是虚存值,不是物理内存,所以也只能参考。
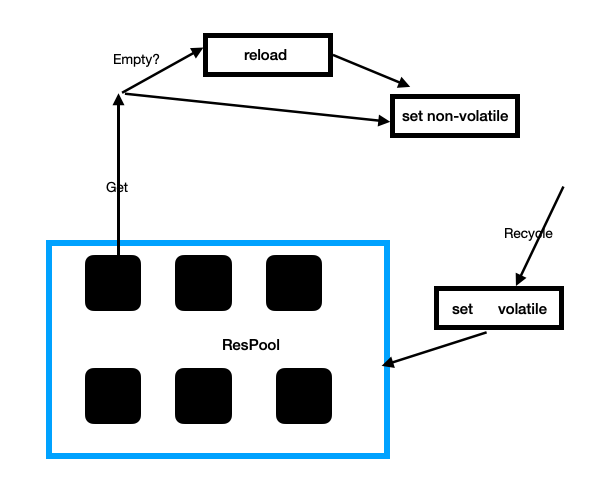 基于purgeable state的资源池管理方式
Memoryless Resource
除了purgeable state之外,metal的resource还可以指定它的storage mode。Storage mode用于指定mtl资源的被cpu和gpu访问的途径和存储优化。对于用于做rt的texture,有一个特殊的存储模式叫做memoryless。
我们知道对于tbdr的设备,我们在创建一个rt之后,rt的真正访问是在gpu的cache上的,除非我们显示的需要读取它才需要把整个资源从gpu cache resolve到memory上的,所以在很多情况,我们是根本不需要存在一个memory上的那一份rt的。例如你的只用作深度测试的深度图。这样的资源在iOS上可以声明为memoryless的storage mode,这样整个mtltexture对象在创建后其实并不会产生一个memory上的内存占用,只会在gpu的cache上产生临时的对象,并且用后也不会resolve回内存,相当于我们节省了整个rt的内存开销。
基于purgeable state的资源池管理方式
Memoryless Resource
除了purgeable state之外,metal的resource还可以指定它的storage mode。Storage mode用于指定mtl资源的被cpu和gpu访问的途径和存储优化。对于用于做rt的texture,有一个特殊的存储模式叫做memoryless。
我们知道对于tbdr的设备,我们在创建一个rt之后,rt的真正访问是在gpu的cache上的,除非我们显示的需要读取它才需要把整个资源从gpu cache resolve到memory上的,所以在很多情况,我们是根本不需要存在一个memory上的那一份rt的。例如你的只用作深度测试的深度图。这样的资源在iOS上可以声明为memoryless的storage mode,这样整个mtltexture对象在创建后其实并不会产生一个memory上的内存占用,只会在gpu的cache上产生临时的对象,并且用后也不会resolve回内存,相当于我们节省了整个rt的内存开销。
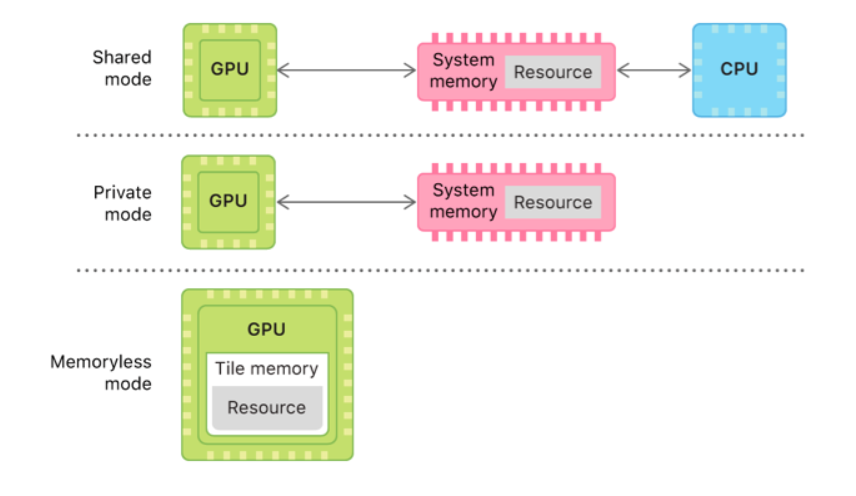 在iOS上对于所有的不需要resolve的rt(或storeaction设置为don’t care)都应该设置为memoryless。注意如果声明了meoryless但是实际又去读取了它则会产生crash。
Memoryless的资源同样不计入mem foot。
Metal resource heap
iOS中xture和buffer等资源通常可以直接从mtldevice上创建。但是能带来更多内存优化的方法是从mtlheap上创建。
Metal Resouce Heap是一个抽象的用于创建GPU资源的heap,它其实是维护了一个内存池。我们可以从1个MTLHeap上subllocate多个texure 或者buffer,这样做有很多好处:
首先它减轻了资源创建的时间开销,因为heap的后面是一个可复用的内存池。
然后因为mtlheap的内存可能被系统动态的压缩不常用的区域,所以基于mtlheap可以减少内存占用。
一个mtlheap上的subllocate资源拥有相同的storage mode和cpu cache mode。另外mtlheap需要整体设置purgeable state,而不能每个资源单独设置。所以实际使用中我们也要有很多的mtlheap组成的池,那些storage mode相同,purgeable state相同的资源从一个heap上分配,另外metal文档提到单个heap也不能过大,因为对heap的压缩将影响其性能。
另外mtlheap上分配的资源支持alias机制,下面一段会讲。
Resource Alias
从mtlheap上创建的资源支持alias机制,alias也是iOS上对gpu资源的一个独有优化机制,它是指一个被标记为alias的资源A可以被mtlheap重用,只要重用的资源B同A有相同的资源格式,只是内容不一致,并且逻辑上要保证A和B不会被GPU同时使用。
一个典型的使用场合是后处理链,在这里面要涉及很多后处理阶段,每个后处理阶段用到不同的rt,但是这些rt不会被同时使用,我们就可以把这rt做成alias的,然后在后面阶段不断被重用,但是分配的内存一直都是那一个。这个过程要注意使用fence或event来保证共享这块内存的rt不会被同时使用到,这里我们的做法应该是从mtlheap创建一个rt,然后执行第一步后处理,然后插入一个fence,调用它的makealiasable,然后再创建第二个rt,执行第二步后处理…依次下去。
iOS通过alias为我们在保持逻辑层有多个资源的同时,做到了一个底层的内存共享。
关于shader
Shader也会占用较多的显存。除了常规的减少shader变体之外,我们还应该利用metal的shaderlibrary的预编译,预先将metal shader编译成native的mtllibrary,运行时从library中加载shader function,而不是动态从源码编译shader 。
首先从mtllibrary加载要更快,另外mtllibrary本身不占用物理内存,只占用虚存,只会在我们用到哪些shader的时候才产生内存占用,且由于native code本身体积也很小,占用内存少。而动态编译shader会将源码载入内存进行便于,源码体积大本身就会产生更大的内存脚印。
3.2 UE的fmalloc
对于fmalloc的分配,除了常规的减少内存分配次数,尽量对齐内存,减少traray的resize,用inline allocater等栈模拟等方法之外,在iOS上还有一些额外可以尝试的操作。
UE使用一个自带的内存池(Fmalloc)去进行内存的分配释放管理,预先分配整段内存,避免malloc产生磁盘碎片,这个过程会产生前面提到的所有内存池都会有的对齐浪费和页空白浪费。这部分浪费的内存显示在了LLm的malloc unused项目里。
其实对于iOS来说,iOS底层已经实现了类似的malloc小内存池,所以在项目里可以实验一下在iOS上不采用UE的fmalloc而直接用malloc交给iOS的内存池管理,对比下内存用量的区别,对于不同的项目这个哪个更好不好说,但是可以试一下。即使最终发现使用UE的fmalloc还是更优的话,还是可以试一下对于256B以内的小内存直接使用iOS的malloc对比测试一下,因为iOS的nano malloc对于小内存还做了额外的优化。
Vm_copy
前面提到了iOS上使用vm_copy来明确的使用copy on write优化,所以我们应该在代码里大量的对于大块内存的memcpy换成vm_copy,除非你发现这里的copy时间是个瓶颈。这种优化对于图形程序的收益是很大的,一个典型的场景,我们从文件加载模型数据,然后将其copy到申请的一个mtlbuffer上,在copy之后我们几乎不会对这个内存做更改,如果使用vm_copy,这个copy的操作就剩下了,也减少了内存脚印。
3.3其他
代码段内存
另外对于iOS程序来说,代码段本身也有可能是个大头,这部分可以被swap out,所以当内存真正吃紧的时候危害相对没这么大,但还是可以想办法减小。包括减少代码体积,减少模板的使用,strip掉调试符号,将一些iOS上不会用到的UE的plugin去掉等。
对iOS系统lowmemorywarning的响应
iOS系统会根据不同的机型制定该机型内存告警的级别,如xcode memory gauge上面显示的一样,到达红色区域(如iphonexr到达2.1G)就会触发内存告警,你的程序不能无视内存告警,如果在内存告警到达时不能有效的尽快减轻内存负担,系统将会很快结束该进程以回收内存。我们需要在收到didreceivememorywarning的时候额外释放大量任何可以释放但不会导致程序异常的内存,例如你的各种cache,这也可以大大减少系统异常退出的几率。
在iOS上对于所有的不需要resolve的rt(或storeaction设置为don’t care)都应该设置为memoryless。注意如果声明了meoryless但是实际又去读取了它则会产生crash。
Memoryless的资源同样不计入mem foot。
Metal resource heap
iOS中xture和buffer等资源通常可以直接从mtldevice上创建。但是能带来更多内存优化的方法是从mtlheap上创建。
Metal Resouce Heap是一个抽象的用于创建GPU资源的heap,它其实是维护了一个内存池。我们可以从1个MTLHeap上subllocate多个texure 或者buffer,这样做有很多好处:
首先它减轻了资源创建的时间开销,因为heap的后面是一个可复用的内存池。
然后因为mtlheap的内存可能被系统动态的压缩不常用的区域,所以基于mtlheap可以减少内存占用。
一个mtlheap上的subllocate资源拥有相同的storage mode和cpu cache mode。另外mtlheap需要整体设置purgeable state,而不能每个资源单独设置。所以实际使用中我们也要有很多的mtlheap组成的池,那些storage mode相同,purgeable state相同的资源从一个heap上分配,另外metal文档提到单个heap也不能过大,因为对heap的压缩将影响其性能。
另外mtlheap上分配的资源支持alias机制,下面一段会讲。
Resource Alias
从mtlheap上创建的资源支持alias机制,alias也是iOS上对gpu资源的一个独有优化机制,它是指一个被标记为alias的资源A可以被mtlheap重用,只要重用的资源B同A有相同的资源格式,只是内容不一致,并且逻辑上要保证A和B不会被GPU同时使用。
一个典型的使用场合是后处理链,在这里面要涉及很多后处理阶段,每个后处理阶段用到不同的rt,但是这些rt不会被同时使用,我们就可以把这rt做成alias的,然后在后面阶段不断被重用,但是分配的内存一直都是那一个。这个过程要注意使用fence或event来保证共享这块内存的rt不会被同时使用到,这里我们的做法应该是从mtlheap创建一个rt,然后执行第一步后处理,然后插入一个fence,调用它的makealiasable,然后再创建第二个rt,执行第二步后处理…依次下去。
iOS通过alias为我们在保持逻辑层有多个资源的同时,做到了一个底层的内存共享。
关于shader
Shader也会占用较多的显存。除了常规的减少shader变体之外,我们还应该利用metal的shaderlibrary的预编译,预先将metal shader编译成native的mtllibrary,运行时从library中加载shader function,而不是动态从源码编译shader 。
首先从mtllibrary加载要更快,另外mtllibrary本身不占用物理内存,只占用虚存,只会在我们用到哪些shader的时候才产生内存占用,且由于native code本身体积也很小,占用内存少。而动态编译shader会将源码载入内存进行便于,源码体积大本身就会产生更大的内存脚印。
3.2 UE的fmalloc
对于fmalloc的分配,除了常规的减少内存分配次数,尽量对齐内存,减少traray的resize,用inline allocater等栈模拟等方法之外,在iOS上还有一些额外可以尝试的操作。
UE使用一个自带的内存池(Fmalloc)去进行内存的分配释放管理,预先分配整段内存,避免malloc产生磁盘碎片,这个过程会产生前面提到的所有内存池都会有的对齐浪费和页空白浪费。这部分浪费的内存显示在了LLm的malloc unused项目里。
其实对于iOS来说,iOS底层已经实现了类似的malloc小内存池,所以在项目里可以实验一下在iOS上不采用UE的fmalloc而直接用malloc交给iOS的内存池管理,对比下内存用量的区别,对于不同的项目这个哪个更好不好说,但是可以试一下。即使最终发现使用UE的fmalloc还是更优的话,还是可以试一下对于256B以内的小内存直接使用iOS的malloc对比测试一下,因为iOS的nano malloc对于小内存还做了额外的优化。
Vm_copy
前面提到了iOS上使用vm_copy来明确的使用copy on write优化,所以我们应该在代码里大量的对于大块内存的memcpy换成vm_copy,除非你发现这里的copy时间是个瓶颈。这种优化对于图形程序的收益是很大的,一个典型的场景,我们从文件加载模型数据,然后将其copy到申请的一个mtlbuffer上,在copy之后我们几乎不会对这个内存做更改,如果使用vm_copy,这个copy的操作就剩下了,也减少了内存脚印。
3.3其他
代码段内存
另外对于iOS程序来说,代码段本身也有可能是个大头,这部分可以被swap out,所以当内存真正吃紧的时候危害相对没这么大,但还是可以想办法减小。包括减少代码体积,减少模板的使用,strip掉调试符号,将一些iOS上不会用到的UE的plugin去掉等。
对iOS系统lowmemorywarning的响应
iOS系统会根据不同的机型制定该机型内存告警的级别,如xcode memory gauge上面显示的一样,到达红色区域(如iphonexr到达2.1G)就会触发内存告警,你的程序不能无视内存告警,如果在内存告警到达时不能有效的尽快减轻内存负担,系统将会很快结束该进程以回收内存。我们需要在收到didreceivememorywarning的时候额外释放大量任何可以释放但不会导致程序异常的内存,例如你的各种cache,这也可以大大减少系统异常退出的几率。
 iOS内存问题排查常用工具
UE自带的memoryreport
这是最简单方便的估计UE主要资源的方法,里面集成了一些指令,可以看到常用资源如贴图,uobject等的详细清单,内存,但是这里面的内存值都是估计的,只供参考。
UE自带的obj list 指令
用于列出任意uobject类型的实例清单,对于内存泄露和因uobject产生的内存优化很重要。
UE自带的obj refs 指令
用于列出任何uobject实例的引用链条,可以在我们通过obj list找到泄露的对象后继续追查它未被GC的原因。
UE自带的LLM工具
在《Android 内存分析和优化》中详细讲了UE这个工具的实现,它可以将UE范畴内分配的内存按tag列出,对显存资源也能做出较准确的估计。
Xcode的allocation
这个就是平台层面的工具,但是也是最全面的,它获取整个iOS程序的内存情况,进行内存分布分析,泄露查找。这里面可以按照各种tag列出整个虚存空间的分配情况,还可以看到如下图整个程序的虚存空间每个地址上的分配情况,tag,大小,映射的物理内存大小,类似于Android平台上的pmap。
iOS内存问题排查常用工具
UE自带的memoryreport
这是最简单方便的估计UE主要资源的方法,里面集成了一些指令,可以看到常用资源如贴图,uobject等的详细清单,内存,但是这里面的内存值都是估计的,只供参考。
UE自带的obj list 指令
用于列出任意uobject类型的实例清单,对于内存泄露和因uobject产生的内存优化很重要。
UE自带的obj refs 指令
用于列出任何uobject实例的引用链条,可以在我们通过obj list找到泄露的对象后继续追查它未被GC的原因。
UE自带的LLM工具
在《Android 内存分析和优化》中详细讲了UE这个工具的实现,它可以将UE范畴内分配的内存按tag列出,对显存资源也能做出较准确的估计。
Xcode的allocation
这个就是平台层面的工具,但是也是最全面的,它获取整个iOS程序的内存情况,进行内存分布分析,泄露查找。这里面可以按照各种tag列出整个虚存空间的分配情况,还可以看到如下图整个程序的虚存空间每个地址上的分配情况,tag,大小,映射的物理内存大小,类似于Android平台上的pmap。
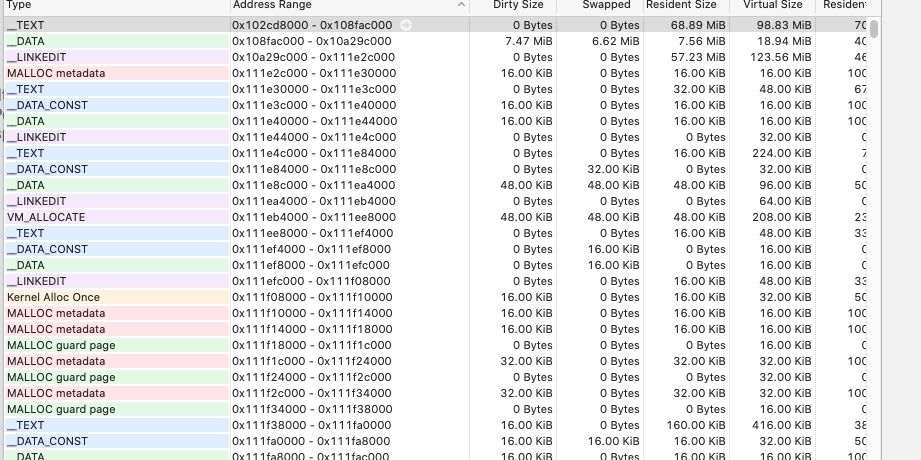 还可以插入generation,来定位在某个时间段之内增长的内存。
注意这个工具里面的几个分类表述,all heap是指从malloc途径的分配,anonymous VM是指所有不带tag的vm_allocate,而UE的fmalloc因为带了255的tag,所以不在anonymous VM分类下,而是在all vm region下面的memory tag 255下。
还可以插入generation,来定位在某个时间段之内增长的内存。
注意这个工具里面的几个分类表述,all heap是指从malloc途径的分配,anonymous VM是指所有不带tag的vm_allocate,而UE的fmalloc因为带了255的tag,所以不在anonymous VM分类下,而是在all vm region下面的memory tag 255下。
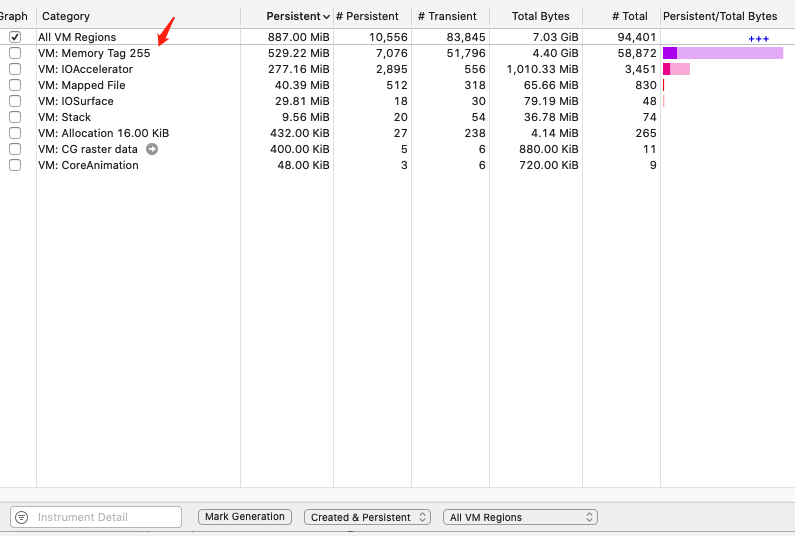 此外Xcode中的leaker,graph capture中的gpu memory,以及memorygraph都是比较有用的排查iOS内存问题和做优化的工具。Memory graph里面就列出了所有程序范畴内的vmobject分布及之间的关系。
总的来说,相比较与其他平台,iOS是一个从操作系统层面就极度追求优化的一个平台,提供了大量平台特有的内存优化手段,这使得同样的程序可以在iOS上比其他平台都有少的多的内存占用,使及时对于大量只有2G内存的iOS设备仍然能够良好的体验游戏,而我们不能无视这些手段,需要利用好iOS提供给我们的武器去优化程序的内存使用。
此外Xcode中的leaker,graph capture中的gpu memory,以及memorygraph都是比较有用的排查iOS内存问题和做优化的工具。Memory graph里面就列出了所有程序范畴内的vmobject分布及之间的关系。
总的来说,相比较与其他平台,iOS是一个从操作系统层面就极度追求优化的一个平台,提供了大量平台特有的内存优化手段,这使得同样的程序可以在iOS上比其他平台都有少的多的内存占用,使及时对于大量只有2G内存的iOS设备仍然能够良好的体验游戏,而我们不能无视这些手段,需要利用好iOS提供给我们的武器去优化程序的内存使用。




|


【本文地址】